

下記の記事でPower Appsとは何かについて紹介しました。

では、具体的にPower Appsの活用方法や使い方について、実際にアプリを作成し、その例を示しながら解説します。
実装に必要な関数、変数、テーブル設計の知識を、IT初心者やPower Apps初心者にもわかりやすく解説します。Power Appsの導入を検討されている方は、ぜひ参考にしてください!
テーブル設計と画面開発を一つの記事にまとめると長くなりすぎるので、二つの記事に分けて解説することにします。
本記事では、テーブル設計を中心に、テーブル設計の基礎概念や設計時の注意点について詳しく説明します。
作成物の概要
今回の作成物は、社内掲示板アプリです。
メイン機能としては
- 掲示板の一覧表示や投稿といった基本機能を備えています。
- 投稿には「雑談」、「告知」の二種類があります。
- 投稿一覧でタイトルをクリックすると、該当する投稿の詳細画面に遷移し、その画面でコメントを投稿することが可能です。
- 投稿一覧でステータス、投稿のタイトル、分類、コメント数、投稿者、更新日時を表示する。
- 投稿を閲覧済みの場合はステータスが「既読」、未閲覧の場合は「未読」、自分が投稿した場合は「自分の投稿」と表示されます。
- 投稿一覧画面で、ドロップダウンでステータスや分類を絞り込むことができます。
画面構成は以下の3つで構成されています:
- 投稿一覧画面
- 新規投稿画面
- 投稿詳細画面
それぞれの画面イメージは以下となります
▼投稿一覧画面

▼新規投稿画面
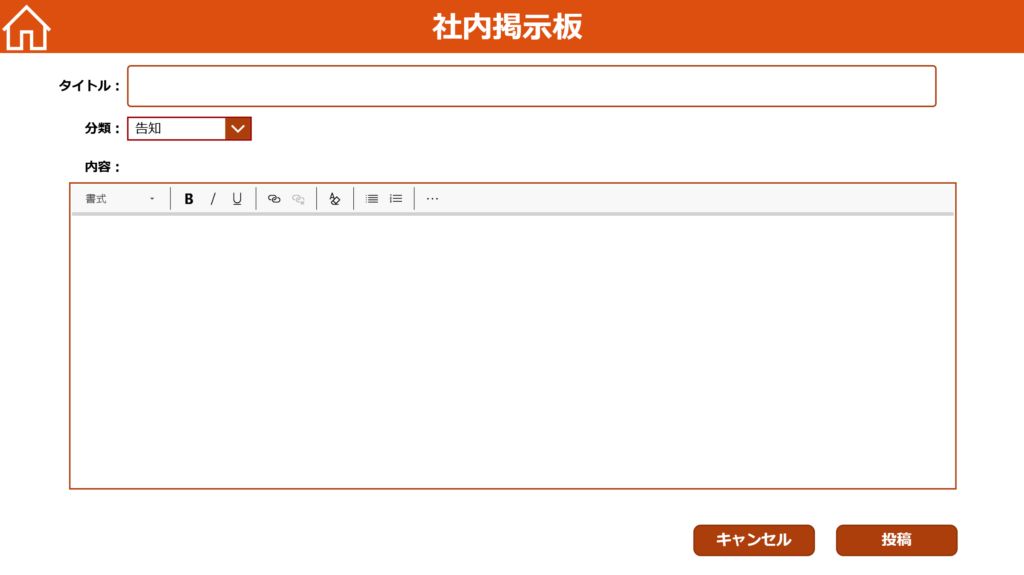
▼投稿詳細画面
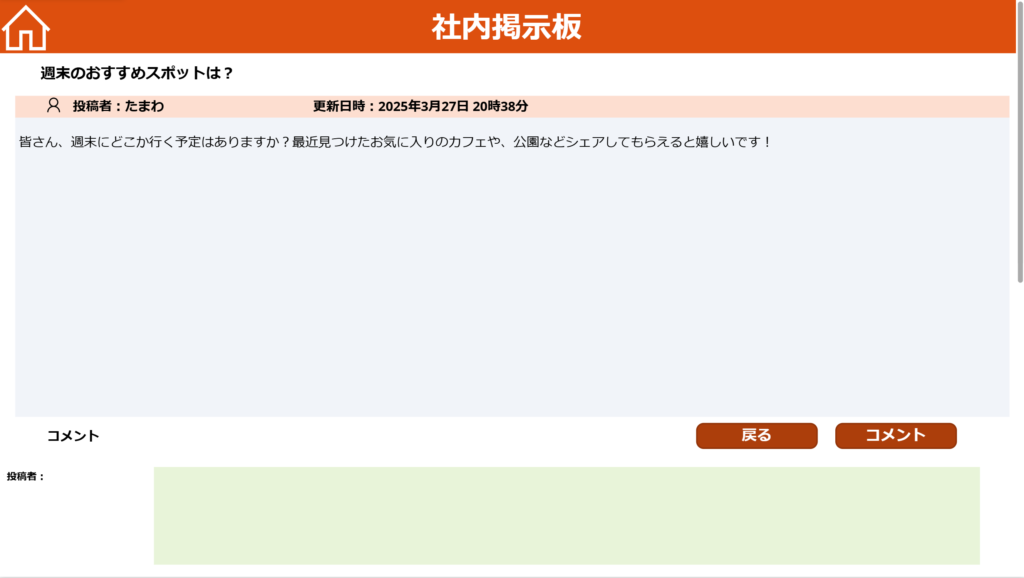
テーブル設計の基礎知識
社内掲示板アプリのテーブル設計を解説する前に、基本的なテーブル設計の知識を簡単に紹介します。
IT初心者やデータベース構築が初めての方にとって参考になればと思います。
すでにテーブル設計の知識がある場合は、この部分をスキップして構いません。
マスタテーブルとトランザクションテーブル
データベースには、マスタテーブルとトランザクションテーブルという2種類のテーブルがあります。
マスタテーブルは、データベース内で基礎的な情報を管理するテーブルです。その特徴は、データの変更が少ない点にあります
一方、トランザクションテーブルは、は動的な情報を管理するテーブルで、データの追加、更新、削除といった変更が頻繁に行われます。これらのテーブルを分類することは、正規化(Database normalization)の目的を達成するための重要な設計手法の一部です。
テーブルを正規化する目的は、データの冗長性を削減し、テーブル構造をより論理的かつ効率的にし、クエリの実行速度を向上させることです。
例えば、投稿一覧画面のテーブルを正規化せずに設計すると、
テーブルがこんな感じになります↓

一個の投稿に対して誰が既読なのか未読なのかを特定するためにステータス列と閲覧者列が重複し、コメント数をカウントするためにコメント列とコメント作成者列も重複してしまうので、テーブルの内容が非常に複雑で分かりにくい状態です
このように重複のデータが多いテーブルで、アプリ側からデータを取得する際にクエリを工夫しないといけないので(一意のデータを抽出したり特定のデータをフィルタリングしたり)、結果的にクエリが非効率化になってしまいます。
なので、テーブルを設計・構築する際に正確に正規化することがとても重要です。
リレーションシップ、PK(主キー)とFK(外部キー)
テーブルのリレーションシップは、テーブル間の関連性や結びつきを表します。これにより、複数のテーブルを効率的に連携させ、データを整合性のある形で管理・利用することができます。
また、テーブル間のリレーションシップを構築するために、PK(主キー)とFK(外部キー)は重要な役割を果たしますので、PK列とFK列の選定は非常に重要です。
主キーと外部キーのそれぞれの役割と特徴は:
- 主キー(PK: Primary Key):
- 役割: 主キーはテーブル内の各行(レコード)を一意に識別するためのキーです。一つのテーブル内で、主キーの値は重複してはいけません。また、主キーにはNULL値を含めることができません。
- 特徴:
- ユニークであること。
- 必須項目(NULL値不可)。
- 通常、ID番号など、レコードを識別するための列が主キーとして使用されます。
- 外部キー(FK: Foreign Key):
- 役割: 外部キーは、あるテーブルが別のテーブルを参照するためのキーです。リレーションシップを作ることで、複数のテーブル間のデータの関連付けが可能になります。
- 特徴:
- 外部キーは、参照先テーブルの主キー(PK)を指します。
- 子テーブルで設定され、親テーブルを参照します。
- 参照整合性を保つために、削除や更新時の動作ルールを指定することもできます。
ここでは部署テーブル、社員テーブル、プロジェクトテーブル、プロジェクト社員中間テーブル、社員詳細テーブルを例にリレーションシップの種類を説明します。
▼部署テーブル
| DepartmentID(PK) | DepartmentName |
| 1 | 営業部 |
| 2 | 開発部 |
▼社員テーブル
| EmployeeID(PK) | Name | DepartmentID(FK) |
| 1 | 山田太郎 | 1 |
| 2 | 鈴木花子 | 1 |
| 3 | 高橋一郎 | 2 |
▼社員詳細テーブル
| EmployeeID(PK, FK) | Phone | Address | |
| 1 | yamada@example.com | 080-1234-5678 | 東京都〇〇区 |
| 2 | suzuki@example.com | 080-2345-6789 | 東京都△△区 |
| 3 | takahashi@example.com | 080-3456-7890 | 東京都□□区 |
▼プロジェクトテーブル
| ProjectID(PK) | ProjectName | StartDate |
| 101 | 新製品開発 | 2025-01-15 |
| 102 | 営業戦略強化 | 2025-02-01 |
| 103 | 経理システム改善 | 2025-02-20 |
▼社員プロジェクト中間テーブル
| EmployeeID(FK) | ProjectID(FK) |
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
| 3 | 103 |
リレーションシップには、次の三つの種類があります:
- 一対一
- 一対多
- 多対多
上記の例で説明すると
社員テーブルは社員詳細テーブルに対して一対一のリレーションシップを持っています。(1人の社員につき1つの詳細情報が関連付けられます)
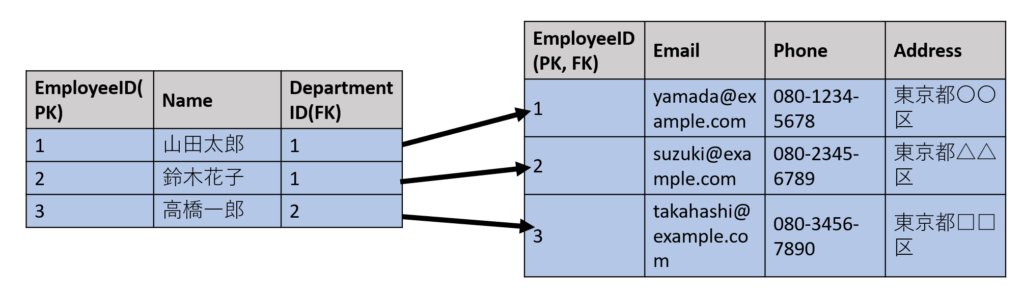
部署テーブルは社員テーブルに対して一対多のリレーションシップを持っています。(一つの部署に複数人の社員)
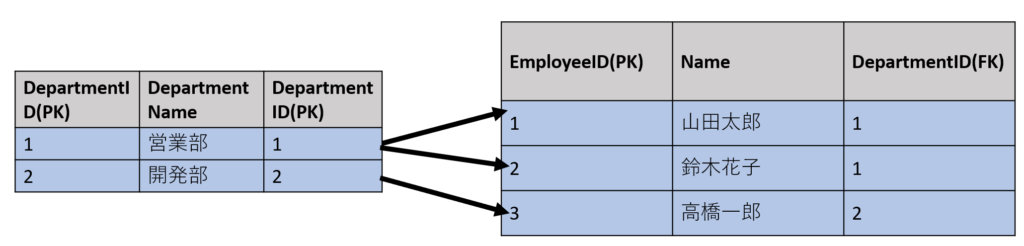
部署テーブルは社員テーブルに対して、一対多のリレーションシップを持っています。(1つの部署に複数の社員が所属します)
多対多の場合はこんな感じの中間テーブルが必要です↓
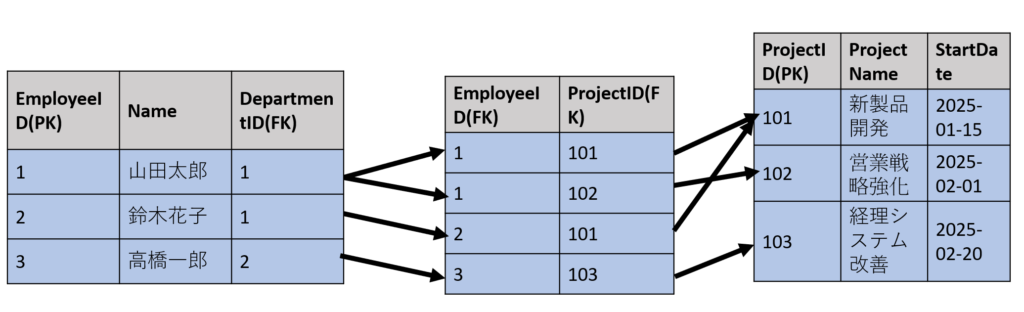
上記は、1人の社員が複数のプロジェクトに所属でき、1つのプロジェクトにも複数の社員が参加できることを示しています。つまり、社員テーブルとプロジェクトテーブルには多対多のリレーションシップを持っています。
監査列
監査列とは、特定のデータが「いつ」「誰によって」「どのように」変更されたかを追跡するために用いられる列のことを指します。
監査列に含まれる情報は作成者、作成日時、更新日時、更新者、削除フラグです。
削除フラグは、データベースのテーブルから物理削除ではなく、論理削除を管理するための列です。
掲示板アプリのテーブル設計
さて、本題に入りましょうー!
前述ではテーブルを正規化することがいかにも重要であることを説明しましたので、
テーブルを正確に正規化することを意識しつつ、掲示板アプリのテーブルを設計しましょう!
今回の掲示板アプリのデータソースをDataverseに選定します。
投稿一覧画面、新規投稿画面、投稿詳細画面の画面イメージに沿って、投稿本文データ、社員データ、既読記録データ、投稿コメントデータを格納するテーブルが必要です。
投稿本文と社員リストの変更頻度が低いと考えられるので、これら2つのテーブルをマスタテーブルとして定義します。
投稿本文のテーブルをBulletinBoardと命名し、監査列を含めて以下のように設計します:
(*Dataverseなので、データの種類を記述します)
| 列名 | データの種類 |
| post_id (PK) | オートナンバー |
| author (FK) | 一行テキスト |
| title | 一行テキスト |
| content | 複数行テキスト |
| type | 一行テキスト |
| created_by | 一行テキスト |
| created_on | 日付と時刻 |
| modified_by | 一行テキスト |
| modified_on | 日付と時刻 |
| delete_flag | はい/いいえ選択肢 |
- post_id列 → 自動採番で生成して投稿のIDを格納します。
- author列 → 投稿者の社員IDデータを格納します。
- title列 → 投稿のタイトルデータを格納します。
- content列 → 投稿の本文データを格納します。
- type列 → 投稿の分類データを格納します。
社員テーブルをEmployeeMasterと命名します:
| 列名 | データの種類 |
| employee_id (PK) | 一行テキスト |
| employee_name | 一行テキスト |
| employee_email | 一行テキスト |
| created_by | 一行テキスト |
| created_on | 日付と時刻 |
| modified_by | 一行テキスト |
| modified_on | 日付と時刻 |
| delete_flag | はい/いいえ選択肢 |
- employee_id列 → 社員IDを格納します。
- employee_name列 → 社員の名前を格納します。
- employee_email列 → 社員のemailを格納します。
1つの投稿に対するコメントデータと既読履歴データを格納するテーブルは、頻繁に変更されるので、トランザクションテーブルに分類します。
既読履歴テーブルをReadに命名し、以下のように設計します:
| 列名 | データの種類 |
| read_id (PK) | オートナンバー |
| post_id (FK) | 一行テキスト |
| reader (FK) | 一行テキスト |
| created_by | 一行テキスト |
| created_on | 日付と時刻 |
| modified_by | 一行テキスト |
| modified_on | 日付と時刻 |
| delete_flag | はい/いいえ選択肢 |
- read_id列 → 既読レコードのIDを自動採番で生成して格納します。
- post_id列 → 投稿のIDを格納します。
- reader_id列 → 既読者の社員IDを格納します。
投稿コメントテーブルをBoardCommentと命名し、以下のように設計します:
| 列名 | データの種類 |
| comment_id (PK) | オートナンバー |
| comment_author (FK) | 一行テキスト |
| post_id (FK) | 一行テキスト |
| comment_content | 複数行テキスト |
| created_by | 一行テキスト |
| created_on | 日付と時刻 |
| modified_by | 一行テキスト |
| modified_on | 日付と時刻 |
| delete_flag | はい/いいえ選択肢 |
- comment_id列 → 投稿のコメントIDを自動採番で生成して格納します。
- comment_author列 → コメントした社員のIDを格納します。
- post_id列 → コメント対象の投稿IDを格納します。
- comment_content列 → コメントの内容を格納します。
Dataverseには既存の監査列がありますが、更新者と作成者の列にM365に登録された名前で自動的に入力・上書きされるので、組織で運用する際に同姓同名の社員がいる場合、重複する可能性があります。
この問題を解消するために、手動で監査列を作成し、名前以外の一意のデータ、例えば社員番号やメールアドレスを登録するように設計しましょう。
まとめ
今回の記事で
- テーブル設計の基本知識、リレーションシップ、テーブル正規化について紹介しました。
- 掲示板アプリのテーブル設計を行い、BulletinBoard、Read、BoardComment、EmployeeMasterという4つのテーブル設計しました。
次の記事では、掲示板アプリの実装を解説します!

